


Lesson Learned da esperienze di Progetti Sottomarini
INTELLIGENZA ARTIFICIALE · INGEGNERIA
Reveal ha sostenuto una delle maggiori compagnie norvegesi, leader nella progettazione e produzione di complessi sistemi di ingegneria a supporto dell’industria petrolifera sottomarina:
Reveal ha sviluppato e consegnato la prima applicazione delle tecnologie semantiche per la (semi)-automazione della fase di Analisi dei Requisiti nell’industria petrolifera sottomarina.
Ricerca semantica e navigazione concettuale per l’industria del petrolio e del gas
Reveal ha assistito uno dei maggiori fornitori Hi-Tech di tecnologia sottomarina in Norvegia, una società leader nella progettazione e produzione dei complessi sistemi di ingegneria a sostegno dell’industria petrolifera sottomarina. Questo settore è particolarmente sensibile al problema del superamento dei costi e dei tempi previsti.
Le dimensioni e i costi dei progetti su larga scala in cui è coinvolta l’azienda in questione (ad esempio il rilascio di nuovi impianti sottomarini per l’estrazione petrolifera nel Mare del Nord) sono caratteristiche fondamentali delle complesse pratiche di ingegneria dei requisiti necessarie per ottimizzarli.
Di conseguenza, i processi di gestione dei requisiti su larga scala sono implementati attraverso testi complessi relativi a richieste internazionali, gare d’appalto e documenti di progettazione e di requisiti del sistema prodotti dai team di ingegneri.
Gli errori di valutazione con conseguente mancato rispetto di budget e date di consegna sono i rischi maggiori in queste fasi, e hanno spesso la loro causa principale in requisiti trascurati e esperienze passate trascurate.
L’industria del settore dell’estrazione petrolifera sottomarina è particolarmente sensibile a queste perdite, a causa dei tempi brevi di consegna ed esecuzione dei progetti, che non permettono la compilazione completa di un database dei requisiti dai documenti contrattuali e allegati. In particolare, le non conformità dei prodotti all’uso previsto hanno imposto ampie rilavorazioni, per garantire che i prodotti siano adatti allo scopo e funzionanti in piena sicurezza.
Semi-automazione delle fasi di analisi dei requisiti
Reveal ha sviluppato e consegnato la prima applicazione di tecnologie semantiche per la (semi) automatizzazione della fase di analisi dei requisiti nel settore di produzione sottomarina di petrolio.
In questo progetto, abbiamo dimostrato nel dominio specifico l’efficacia delle tecniche di Natural Language Processing e Machine Learning nell’automatizzare l’annotazione semantica e la gestione dei documenti coinvolti.
Localizzando le frasi che contengono i requisiti e attribuendogli specifici tipi (ontologici), il progetto ha permesso un supporto estremamente efficace ai progettisti nel rendere disponibile e rapidamente recuperabile l’intero corpo di esperienze rilevanti.
Data l’adozione degli standard www, questi tipi sono ampiamente riutilizzabili in progetti e scenari futuri.
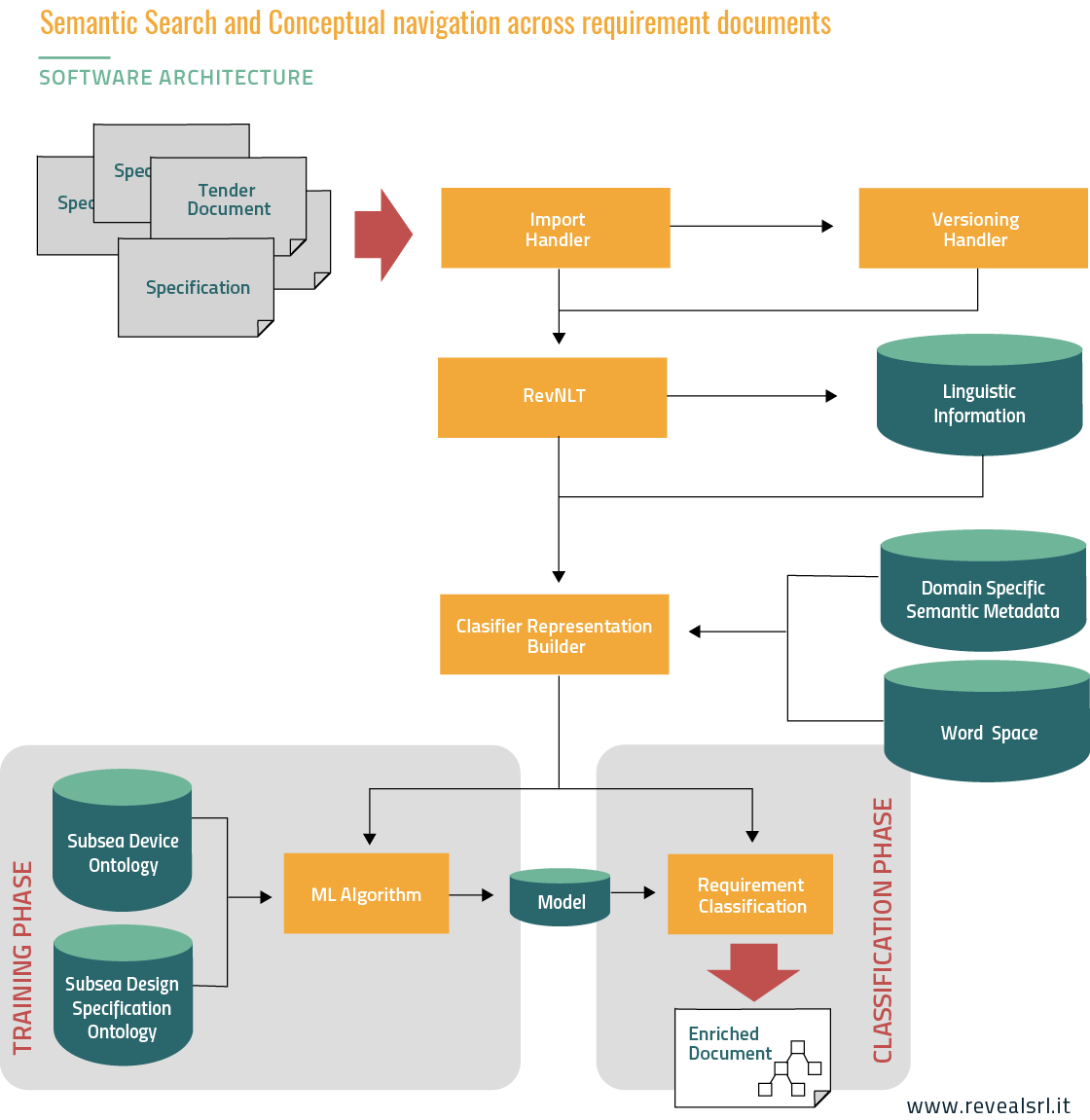
L’ARCHITETTURA:
Illustriamo qui i diversi moduli coinvolti.
- L’Import Handler carica e pre-elabora i documenti relativi ai requisiti, al fine di acquisire una rappresentazione leggibile dai seguenti moduli.
- Il Versioning Handler realizza le funzionalità per gestire il controllo di versioni della documentazione. Quando è disponibile l’aggiornamento di un dato documento, vengono recuperate le differenze tra i documenti per consentire il tracciamento dei requisiti attraverso gli aggiornamenti. Per esempio, quando viene aggiunta una frase che esprime un requisito, il sistema assegnerà un tipo adeguato alla nuova frase, e quindi notificherà l’aggiunta di un nuovo requisito.
- Il Reveal Natural Language Toolkit (RevNLT) implementa tecniche di elaborazione del linguaggio naturale (NLP) per realizzare un’analisi morfosintattica sulla natura dei testi presenti nei documenti. Un esempio di questa analisi è la segmentazione dei documenti in frasi, l’identificazione delle classi principali che caratterizzano grammaticalmente le parole che compongono le frasi (es. nomi, verbi o aggettivi); l’analisi delle frasi, che permette l’estrazione delle costruzioni linguistiche come il complemento soggetto-verbo-oggetto. Nell’architettura complessiva, questo sistema rappresenta un modulo che fornisce informazioni linguistiche utili per costruire una rappresentazione artificiale per l’algoritmo di apprendimento.
- Il Classifier Representation Builder acquisisce ogni frase, seleziona dal sistema NLP le informazioni adeguate necessarie per generare la rappresentazione artificiale utile per l’algoritmo di apprendimento. Alcune informazioni possono essere derivate dal lessico e dalla raccolta terminologica che rappresenta i metadati semantici specifici del dominio. La generalizzazione lessicale è acquisita attraverso il modello Word Space.
- Il Browser concettuale sfrutta le informazioni linguistiche e ontologiche (ad esempio i tipi di apprendimento come “Produzione” o “Controllo qualità”), per supportare la navigazione e l’esplorazione attraverso analoghe istruzioni. Il browser creato permette di recuperare le ultime esperienze (nodi in verde scuro nella figura sottostante), stimare la loro rilevanza in funzione della semantica del testo corrispondente e, di conseguenza, visualizzarle più vicine (o più lontane) alla query di origine (nodi in verde chiaro nella figura), in accordo con i punteggi di rilevanza più alti (o più bassi).
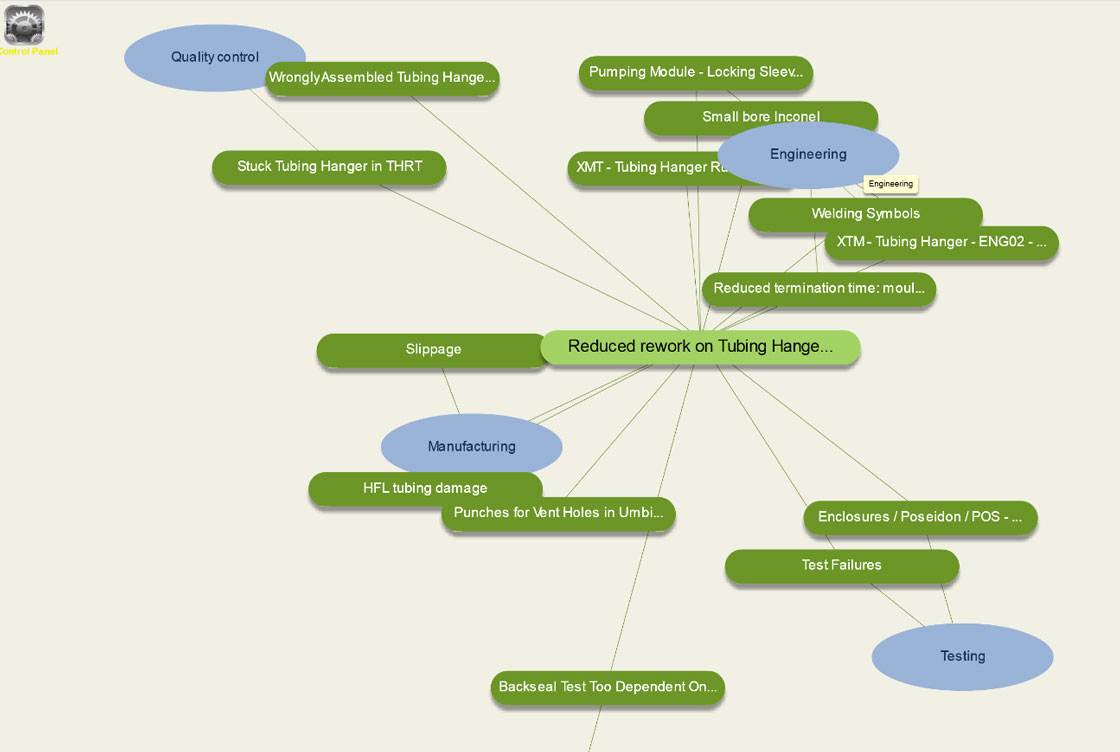
Il motore di ricerca semantico
Un motore di ricerca semantica è stato implementato personalizzando il motore di ricerca Revealer per sfruttare l’informazione ontologica derivata dall’elaborazione semantica realizzata in questo progetto.
COMPITO:
- Recuperare documenti ( e anche passaggi o frasi) dalla raccolta di documenti dell’azienda che si riferiscono a concetti specifici;
- Abilitare un filtro semantico del materiale recuperato (ad es. selezionando solo frasi relative all’analisi della “pressione di progettazione” di un “XMT”);
- Abilitare Report Avanzati dal materiale recuperato (es. raggruppare (clustering) i risultati di un Motore di Ricerca considerando i requisiti specifici coinvolti nei testi recuperati)
Lo sviluppo dell’interfaccia dell’utente è stato realizzato tenendo conto delle seguenti linee guida:
- Espressività: L’interfaccia utente deve esporre tutte le informazioni estratte dal testo.
– Differenze tra frasi
– Entità trovate (norme, componenti e quantità fisiche) - Navigazione: L’UI deve permettere agli utenti di navigare all’interno dei risultati forniti dal sistema in modo da poter sempre recuperare l’insieme dei concetti scoperti dal sistema.
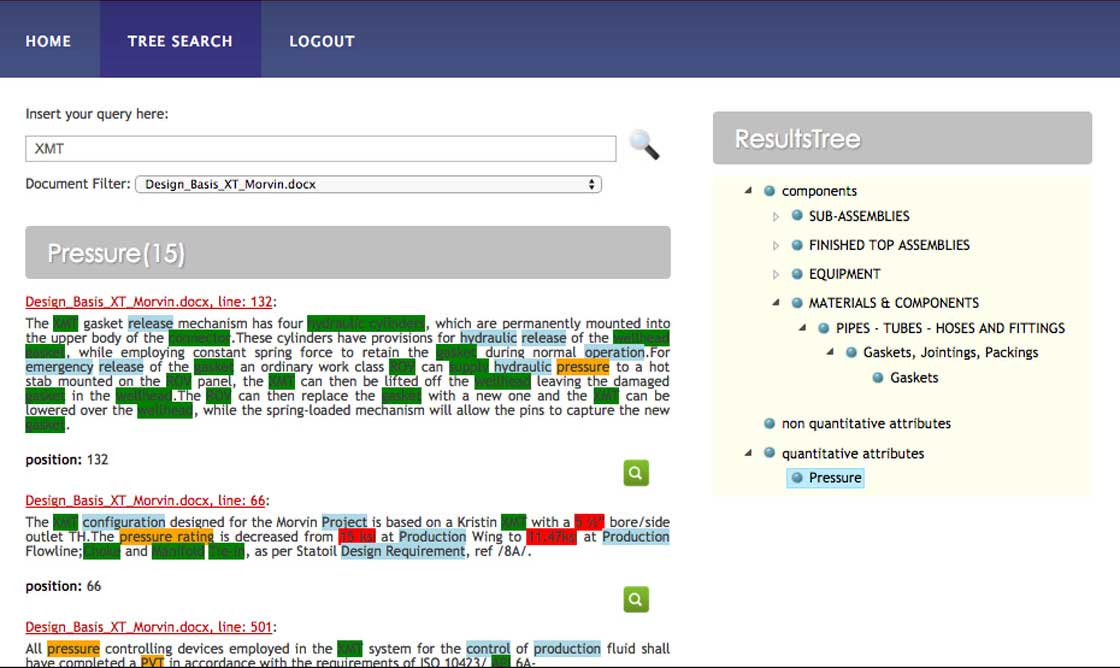
In alto, una schermata di un sottogruppo di risultati del sistema per la query “XMT” quando il criterio “Pressione” è selezionato, con informazioni classificate e codificate a colori. Il codice a colori permette all’utente di concentrarsi rapidamente sul tipo di requisito che la specifica sta dettando.
I requisiti “soft” sono notoriamente difficili da identificare e da tracciare completamente.
Il sistema permette all’ingegnere di discriminare rapidamente tra i requisiti quantitativi “hard” (cioè i valori numerici delle prestazioni come pressione, temperatura, velocità, ecc.) e i requisiti “soft” o “modali” più difficili da identificare, che stabiliscono il modo previsto di funzionamento, manutenzione, interazione uomo-macchina. I requisiti “soft” sono notoriamente difficili da identificare e tracciare completamente, il sistema assiste il team di progettazione fornendo i dati in una forma favorevole alla codifica in registri di azione o di interfaccia.