


Ecosistema di Dati per la vostra organizzazione
PRODOTTI • SERVIZI
Il framework di Reveal è costituito da un insieme di servizi modulari che consentono una personalizzazione della soluzione finale, economicamente vantaggiosa. Ogni modulo è dedicato ad un compito specifico, che va dall’elaborazione dei documenti di input, all’elaborazione semantica dei testi fino all’implementazione delle funzioni di retrieval. L’applicazione finale è tipicamente rilasciata come Architettura Orientata a Servizi che può essere rilasciata on premise, o nel cloud di Reveal.

Estrattore di Relazioni per Grandi Organizzazioni
Quando si ha a che fare con raccolte documentali su larga scala, i tradizionali motori di ricerca mostrano il loro limite nel supportare una vasta gamma di richieste complesse.
Ad esempio, se da un lato un’organizzazione può essere interessata a conoscere tutte le unità che svolgono una specifica attività e tutte le altre unità che ne beneficiano, dall’altro un motore di ricerca è in grado di recuperare solo tutti i documenti che citano l’ufficio di destinazione e le azioni specifiche (forse ambigue).
Per le grandi organizzazioni è fondamentale adottare tecniche per estrarre automaticamente la conoscenza dai testi, poiché la maggior parte delle informazioni preziose sono solo implicite (o nascoste) al loro interno.
È ancora necessaria un’attività dispendiosa in termini di tempo per leggere il testo recuperato. D’altra parte, questo tipo di interrogazioni può essere facilmente realizzato da un database, ma le informazioni che servono a popolare un sistema transazionale simile sono riportate solo in documenti non strutturati ed eterogenei.
In questi scenari, è fondamentale adottare tecniche per estrarre automaticamente la conoscenza dai testi, poiché la maggior parte delle informazioni importanti sono solo implicite (o nascoste) al loro interno. Queste informazioni estratte possono essere utilizzate per migliorare l’accesso e la gestione della conoscenza nascosta in grandi corpora di testo. Entità come persone, attività o organizzazioni, costituiscono l’unità più basilare dell’informazione. Inoltre, le occorrenze di entità in una frase sono spesso collegate attraverso relazioni ben definite; ad esempio, le occorrenze di un’unità e le attività in una frase possono essere collegate attraverso relazioni come unità-esegue-attività.
L’estrazione automatica della conoscenza specifica del dominio supporta la creazione di metadati semantici relativi a concetti rilevanti per il dominio (ad es. eventi, luoghi e persone) e le attività dell’Organizzazione.
Questo permette:
- Il tracciamento automatico delle attività
- La ricerca su di esse negli archivi precedenti
- La visualizzazione delle informazioni aggregate in forme significative
- La navigazione attraverso tali ecosistemi informativi
- L’aggregazione intelligente degli obiettivi (conoscenza) e l’analisi (decisioni).
La combinazione efficace con Revealer
RelExt è progettata per essere un componente plug&play per qualsiasi altro motore di Reveal o del Cliente. Può essere incluso in un’applicazione esistente come libreria standard o richiamato come servizio.
In input richiede testi elaborati da RevNLT (il processore linguistico fornito da Reveal) ed estrae l’insieme delle entità e delle relazioni scoperte. Queste possono essere utilizzate nel flusso di lavoro del cliente (ad esempio, popolando grafi di conoscenza) o utilizzate in combinazione con Revealer, il Motore di Ricerca Semantico fornito da Reveal. Questa combinazione è estremamente efficace in quanto l’output di RelExt può essere utilizzato, ad esempio, per aumentare i metadati semantici durante l’indicizzazione e il recupero dei documenti.
Di conseguenza, l’utente può esprimere domande come ad esempio:
“Cerca tutte le frasi che menzionano unità che collaborano in qualche attività con un’unità di input”.
RelExt è interamente implementato in JAVA e può essere incluso in un’applicazione esistente come libreria standard o richiamato come servizio in qualsiasi architettura orientata ai servizi.
Nell’ecosistema dei servizi Reveal, RelExt tipicamente incorpora tutti i servizi coinvolti nell’elaborazione linguistica dei testi al fine di estrarre automaticamente entità e relazioni. Inoltre, fornisce servizi che consentono l’indicizzazione e il recupero di tali informazioni.
Tutti questi processi sono riassunti nei blocchi colorati della figura seguente:
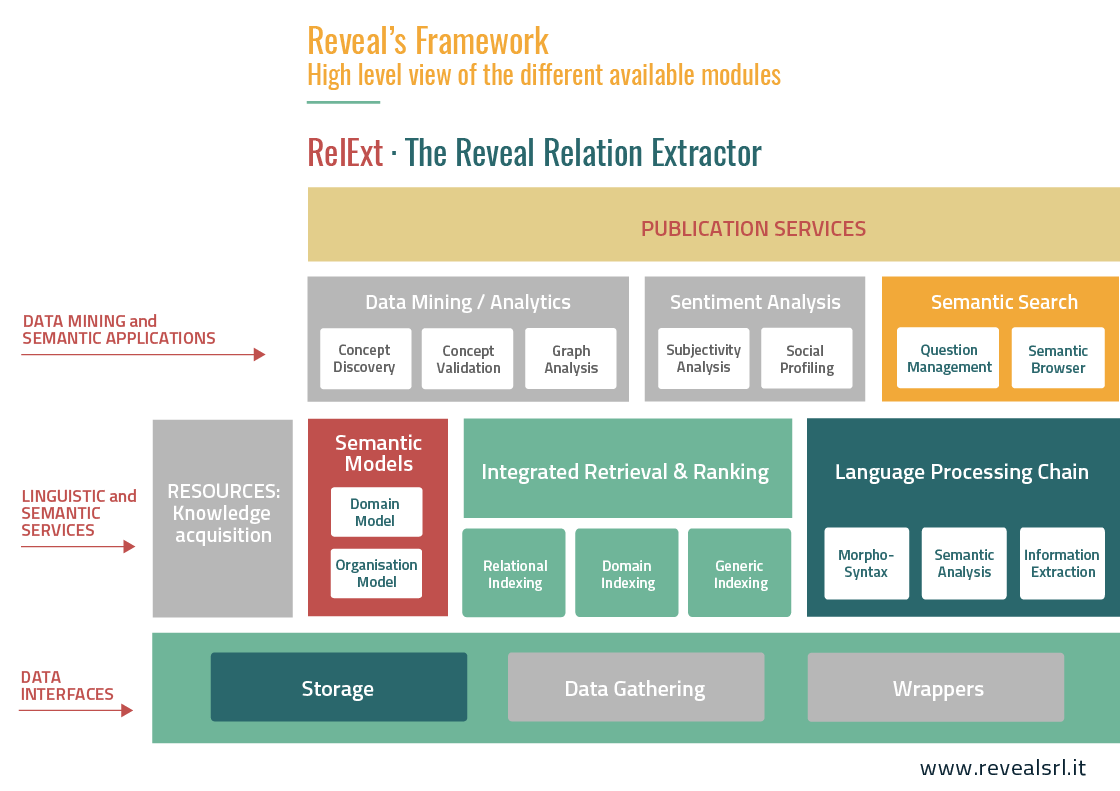
- Interfacce dati: questi servizi permettono di immagazzinare la conoscenza semantica estratta dall’estrattore di relazioni.
- Data mining e applicazioni semantiche: i servizi di ricerca semantica supportano l’utente finale ad accedere facilmente alla conoscenza dei fatti estratta dall’estrattore di relazioni.
- Servizi di pubblicazione: i servizi di pubblicazione consentono l’interazione con l’utente finale, generalmente attraverso applicazioni web personalizzabili in base alle esigenze del cliente.
- Servizi Linguistici e Semantici: questi servizi implementano l’analisi linguistica e l’indicizzazione dei testi di input, insieme alle relazioni semantiche estratte. Servizi dedicati alla gestione del dominio e del modello organizzativo alla base della rappresentazione relazionale.