


Un’azienda innovativa
RICERCA • COMPETENZA
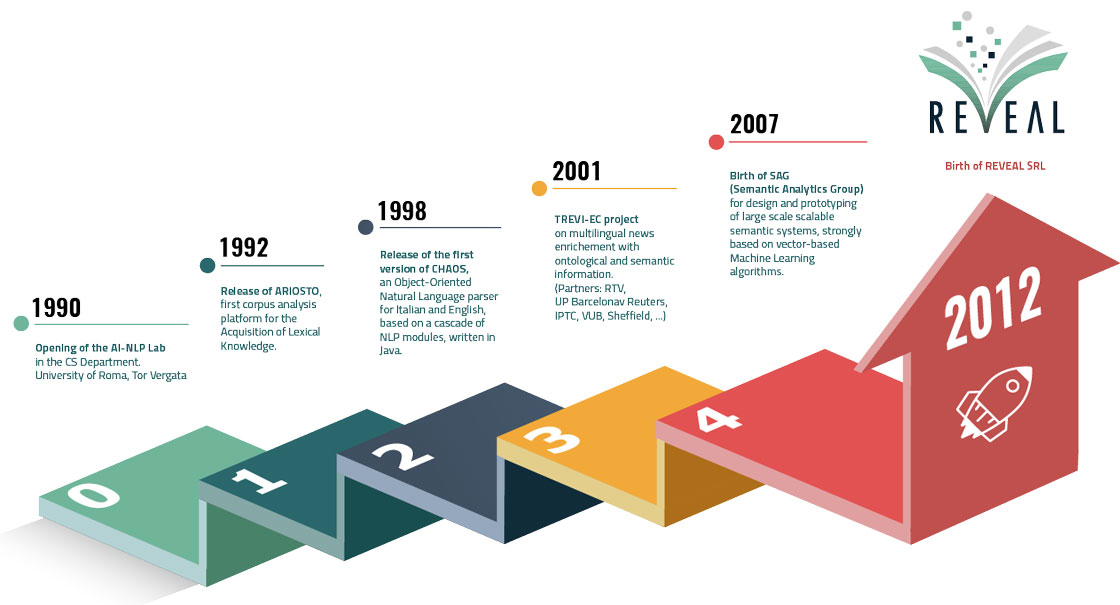
Reveal è una spin-off della Facoltà di Ingegneria dell’Università degli Studi di Roma Tor Vergata dal 2012.
Reveal è specializzata in tecnologie del linguaggio umano, estrazione di informazioni, classificazione e comprensione di documenti, ricerca semantica su basi documentarie, fonti web e ontologie e sentiment analysis.

SAG e Reveal, una storia non troppo breve
L’antenato di Reveal è nato nel 2007 all’Università degli Studi di Roma, Tor Vergata.
La missione del Semantic Analytics Group è la progettazione e la prototipazione di sistemi semantici scalabili su larga scala, fortemente basati su algoritmi di Machine Learning basato su vettori. Questo gruppo è il risultato della decennale fruttuosa ricerca del Laboratorio di IA-NLP.
Missione all’avanguardia
Offrire la progettazione di applicazioni semantiche all’avanguardia basate su complesse tecnologie di apprendimento automatico e data-driven per l’analisi predittiva, ricerca personalizzata, sentiment analysis e dialogo.
Visione pragmatica
Rendere possibile per le organizzazioni l’uso di sistemi avanzati di IA. Una forte attenzione all’alto valore aggiunto, al vantaggio economico e alla sostenibilità.
Reveal mantiene un impegno centrale nella ricerca attiva sostenendo la sperimentazione e il benchmarking sistematico dei risultati tecnologici nei campi dell’IA, del Machine Learning e del Natural Language Processing.
Ricerca attiva
Reveal mantiene un impegno centrale nella ricerca attiva sostenendo la sperimentazione e il benchmarking sistematico dei risultati tecnologici nei campi dell’IA, del Machine Learning e del Natural Language Processing.
Codice etico
Per Reveal l’adozione del Codice Etico rappresenta non solo una dichiarazione pubblica dell’impegno a perseguire il conseguimento degli obiettivi aziendali nella massima osservanza dei dettami e delle policy ma anche la volontà di condividere con tutti i valori fondanti della cultura di impresa ed il rispetto degli interessi legittimi e delle aspirazioni di ognuno.
Politica per la parità di genere
La nostra organizzazione, come ha stabilito nello scopo del sistema di gestione, intende assicurare la parità di genere relativa alla presenza e alla crescita professionale delle donne nell’organizzazione.
Il Team
L’alta competenza contraddistingue il nostro team di ingegneri e ricercatori.
Il nostro team comprende esperti in architetture e sistemi software complessi nell’area dell’Intelligenza Artificiale, del Machine Learning, del Natural Language Processing e della Business Analytics. La natura innovativa delle teorie, dei paradigmi, delle tecnologie e delle buone pratiche legate all’ingegneria delle soluzioni dell’IA richiede la fertilizzazione incrociata di corpi di conoscenza, esperienze e competenze molto diverse. L’azienda fornisce un supporto attivo nelle diverse fasi di inserimento di una soluzione dell’IA nelle istituzioni pubbliche, nelle industrie, così come per i professionisti e per i fornitori di servizi. I risultati supportano l’intero ciclo di vita di un sistema di IA, dalle fasi di progettazione del sistema e di modellazione della conoscenza fino alla consegna rapida di applicazioni intelligenti accurate e prestazionali.

Andriy Shcherbakov
Andriy è il Senior System Architect ed è responsabile dell’analisi, dello sviluppo e dell’integrazione delle applicazioni di Reveal.
Andriy Shcherbakov ha un dottorato in fisica teorica (Laboratorio di Fisica Teproca, JINR, Dubna, Russia 2007) con i principali interessi nella ricerca delle estensioni supersimmetriche della gravità di Einstein e della teoria delle stringhe. I calcoli simbolici utilizzati nella sua ricerca gli hanno permesso di applicare le sue conoscenze nell’informatica per costruire applicazioni basate su Java per vari ambienti.

Antonio Scaiella
Antonio è l’analista dei dati e si occupa dell’analisi e dello sviluppo di moduli di IA che includono il Natural Language Processing e il Machine Learning.
Nel 2019 ha conseguito un Master in Informatica presso l’Università degli Studi di Roma Tor Vergata con una tesi sul Captioning automatico di immagini in italiano utilizzando Reti Neurali complesse.

Monika Kakol
Monika è analista dei dati per Reveal dal 2018.
Si è laureata in Turismo dei paesi dell’area mediterranea nel Collegio Superiore di Teologia e Lettere in Polonia. Ha 18 anni di esperienza nell’editoria e nella comunicazione digitale.
Dal 2017 è iscritta all’Ordine dei Giornalisti del Lazio come giornalista pubblicista.

Daniele Margiotta
Daniele Margiotta ha una laurea Magistrale in scienze informatiche, è interessato alla sviluppo di software che sfruttano tecniche ML.
Grazie al suo percorso da Ricercatore presso l’Università di Roma, Tor Vergata, si è specializzato nell’utilizzo di Sistemi di Apprendimento Neurale sensibili alla Conoscenza Ontologica.
Il Comitato Scientifico

Roberto Basili
Da aprile 2017 è Professore ordinario di Informatica presso il Dipartimento di Ingegneria dell’Impresa dell’Università di Roma, Tor Vergata.
Ricerche: Intelligenza artificiale, Natural Language Processing, Deep Neural Learning, Semantic Content Processing, Web e Multimedia Retrieval (Google Scholar, DBLP, Scopus)
Insegnamento: Intelligenza Artificiale, Database Management Systems, Web Mining & Retrieval, Social Media Analytics.
Roberto Basili dal 2005 è membro del comitato direttivo dell’Associazione Italiana per l’Intelligenza Artificiale (AI*IA). Nel 2014 è stato co-fondatore dell’Associazione Italiana di Linguistica Computazionale (AILC), ed è attualmente membro del comitato direttivo dell’AILC. È autore di più di 190 articoli su riviste e conferenze internazionali nelle aree di IA, NLP, Machine Learning e Web Information Retrieval.
Ha svolto il ruolo di Capo Scienziato in diversi progetti internazionali dagli anni ’90.

Danilo Croce
Da luglio 2015 è Assistente universitario alla facoltà di Informatica presso l’Università di Roma, Tor Vergata.
Ricerche: Deep Learning, Natural Language Processing, Kernel Methods for Semantic Inferences, Question Answering, Dialogue (Google Scholar, DBLP, Scopus)
Insegnamento: Web Mining & Retrieval, Information Retrieval, Data Analytics
La sua attività di ricerca si è concentrata principalmente sullo studio di modelli statistici di machine learning per problematiche complesse di pattern recognition e per la progettazione e lo sviluppo di applicazioni intelligenti nel campo del Natural Language Processing. In particolare, si occupa dello sviluppo di modelli geometrici della semantica lessicale, di tecniche di machine learning (come Metodi basati su Kernel e Deep Neural), insieme allo sviluppo di fenomeni linguistici complessi tipici dei social network e, in generale, dei Big Data: acquisizione automatica di lessici computazionali su larga scala, Question Answering, Web Semantic Search, Social Data & Big Data analytics.