


Ecosistema di Dati per la vostra organizzazione
PRODOTTI • SERVIZI
Il framework di Reveal è costituito da un insieme di servizi modulari che consentono una personalizzazione della soluzione finale, economicamente vantaggiosa. Ogni modulo è dedicato ad un compito specifico, che va dall’elaborazione dei documenti di input, all’elaborazione semantica dei testi fino all’implementazione delle funzioni di retrieval. L’applicazione finale è tipicamente rilasciata come Architettura Orientata a Servizi che può essere rilasciata on premise, o nel cloud di Reveal.

Il processore automatico del linguaggio naturale
RevNLT (Reveal Natural Language Toolkit) è un sistema accurato per l’elaborazione automatica del linguaggio naturale
RevNLT è una cascata di processori linguistici ad alte prestazioni che funziona in italiano e in inglese, è facile da personalizzare, si adatta a specifici domini applicativi e si integra in ambienti applicativi complessi o basati su cloud. Grazie ad un’architettura basata su servizi, RevNLT è altamente efficiente (su un singolo thread, da una CPU standard di un laptop, è in grado di elaborare circa 300 tweet al secondo) e robusto nell’abilitare l’analisi del testo morfosintattico, essenziale per consentire processi avanzati di elaborazione semantica del testo.
Tecniche all’avanguardia di NLP
RevNLT è progettato per essere un componente plug&play per qualsiasi altro motore di Reveal o del Cliente.
È interamente implementato in JAVA e può essere incluso in un’applicazione esistente come libreria standard o invocato come servizio in qualsiasi architettura orientata ai servizi. RevNLT implementa tecniche all’avanguardia per i flussi di lavoro di elaborazione del linguaggio naturale, consentendo l’analisi morfo-sintattica minuziosa del testo contenuto nei documenti.
Alcuni esempi dei tipici flussi di lavoro di analisi supportati sono:
- la segmentazione dei documenti in frasi.
- l’individuazione di classi grammaticali delle parole nelle frasi (ad es. nomi, verbi, aggettivi).
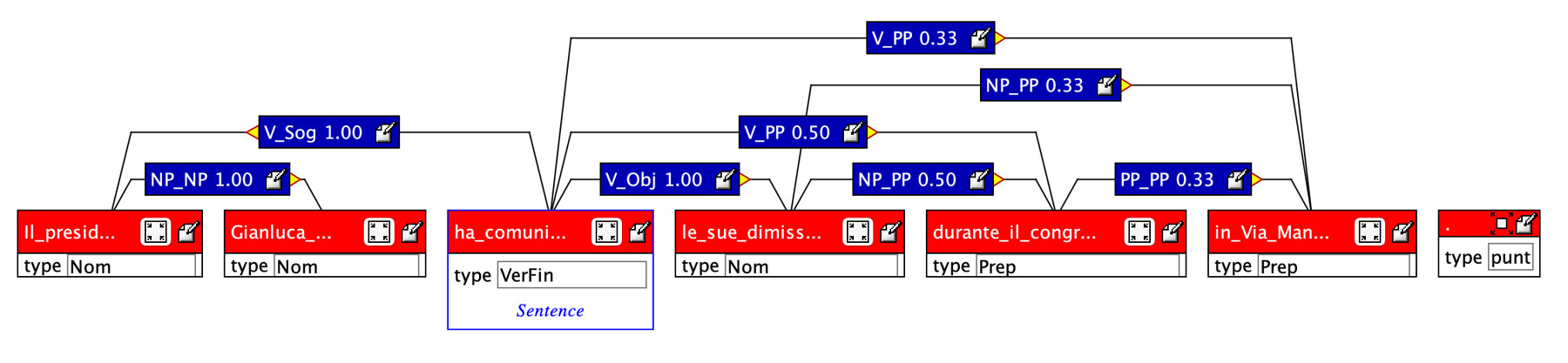
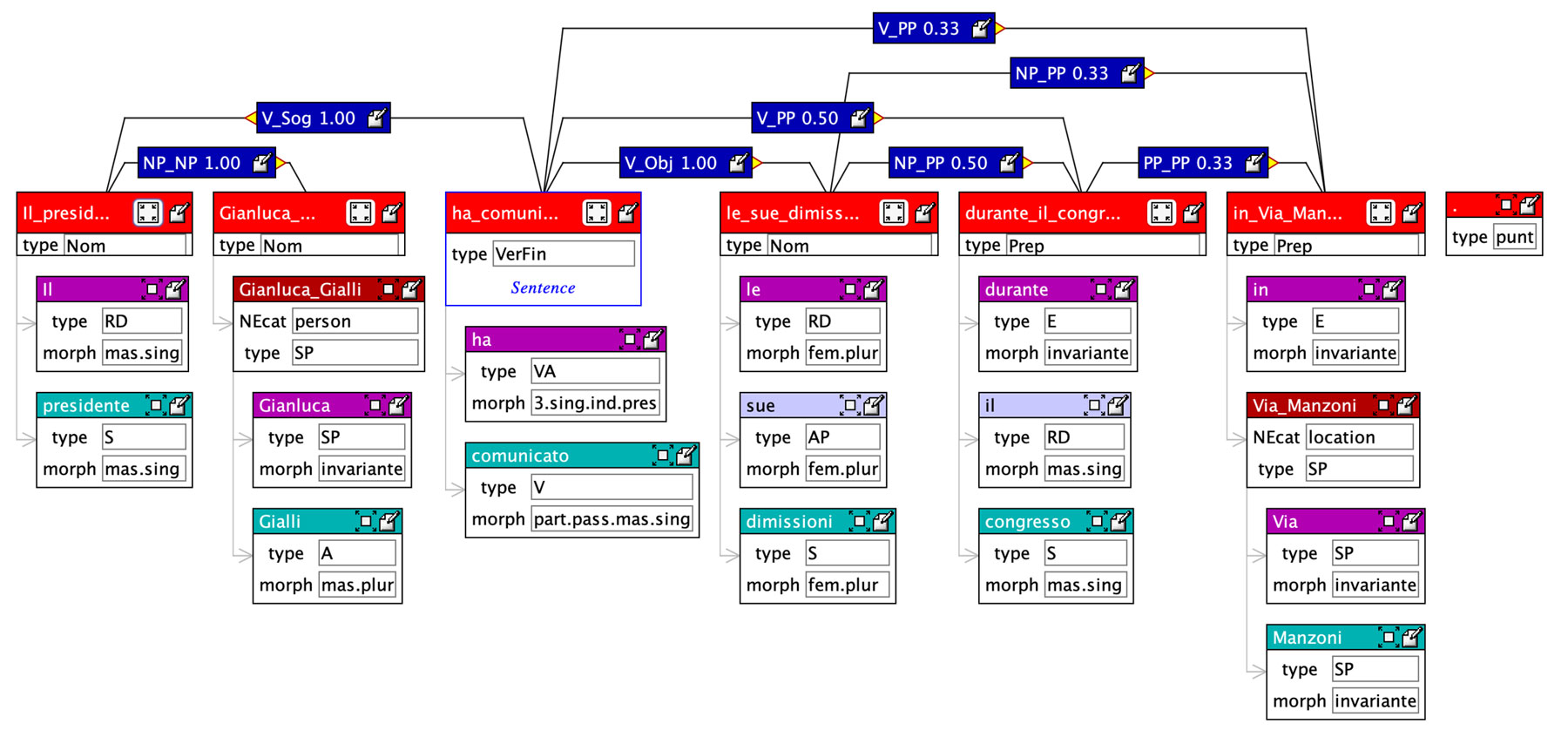
- l’analisi sintattica di testi per l’estrazione di pattern linguistici come triple Soggetto – Verbo – Oggetto nelle frasi.
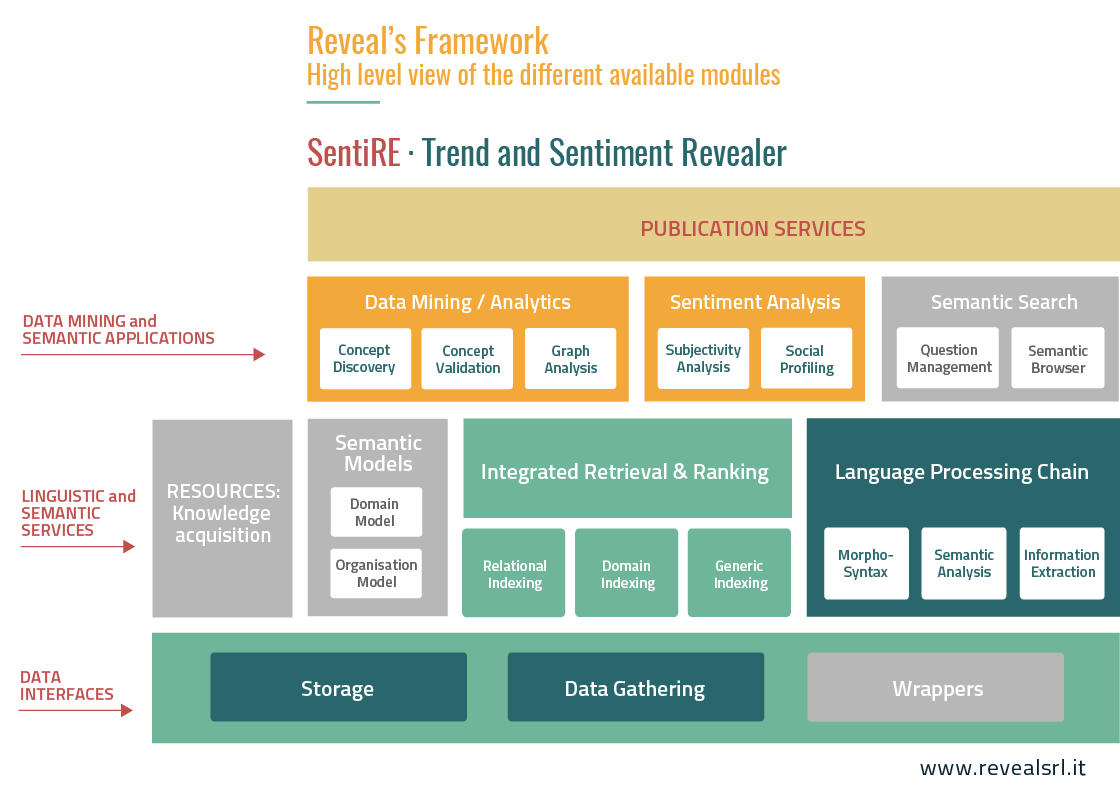
Nell’ecosistema di servizi di Reveal, RevNLT implementa tutte le funzioni dedicate all’Elaborazione Linguistica, essendo la Catena di Elaborazione Linguistica mostrata nella seguente figura nel riquadro verde.
Semplicemente personalizzazione e robustezza
RevNLT è stato già applicato con successo nel settore bancario, nell’industria dei media, nell’ingegneria dei sistemi e nel turismo.
Sebbene esistano molte soluzioni pronte all’uso (e gratuite) per l’elaborazione del linguaggio, uno dei maggiori vantaggi è la sua semplicità nell’essere personalizzato in base alla “sottolingua” utilizzata nel dominio dei clienti. Reveal è proprietaria dell’infrastruttura di personalizzazione che applica approcci statistici e neurali, al fine di garantire la robustezza rispetto a domini eterogenei.