


Data Ecosystem
for your Organization
PRODUCTS • SERVICES
The Reveal framework is made of a set of modular services that allow cost-effective customization of the final solution. Each module is devoted to a specific task, ranging from the processing of the input documents to the semantic elaboration of texts to the implementation of retrieval functions. The final application is typically released as a Service Oriented Architecture that can be released on-premise, or in the Reveal’s cloud.

The Semantic Search Engine
Revealer is a semantic search engine that allows you to retrieve what you are looking for in your document collection, while not knowing the words used in the texts to describe it.
Statistical and ontological models allow you to find the information according to its meaning and publish the results through reports or semantic graphs useful for a more efficient understanding of the answer. Revealer is a service-distributed architecture that easily integrates with other Reveal services, such as the language processor RevNLT to index and retrieve documents depending on a deep understanding of their content.
Users can interact with Revealer NOT only using simple query terms like in traditional search engines. Entire documents or paragraphs can be used as a query.
Revealer is empowered by Information Extraction and Classification subsystems to analyze documents and enrich them with semantic metadata and neural representations reflecting their contents.
Revealer acts as an assistant that reads your texts and assigns to each document, paragraph or sentence a set of “semantic tags” that reflect their meaning and enable powerful and intuitive search functionalities. These must be simple and immediate to be effective: users can interact with Revealer not only using simple query terms like in traditional search engines. Query processors combine NLP and Machine Learning to support the implementation of Question Answering systems, to retrieve specific texts containing the answers to the user’s questions. Moreover, specific Semantic Similarity engines enable the retrieval of information units, getting over the intuitive but limitative term query search in favor of similar documents search: entire information units (documents or paragraphs) can be used as a query.
Moreover, documents can be automatically organized and retrieved according to ontological models provided by the Organization, again using Machine Learning methods. It allows supporting expressive navigations across the retrieved documents, such as semantic graphs.
Highly Modular and Scalable to reduce Cost
It is deployed as a Service Oriented Architecture that can be directly used by the final users through specific web-apps or by other applications by exposing standard web-services.
Revealer and all its components are entirely written in JAVA, including classifiers and language processing modules. It supports large-scale, robust and efficient indexing systems (such as Solr) and it can be easily installed in any environment with reduced costs. It is highly modular in order to efficiently provide a customized solution to the final user. In the Reveal service ecosystem, Revealer typically embodies all services involved in a Semantic Search processes, as summarized in the colored blocks from the following picture:
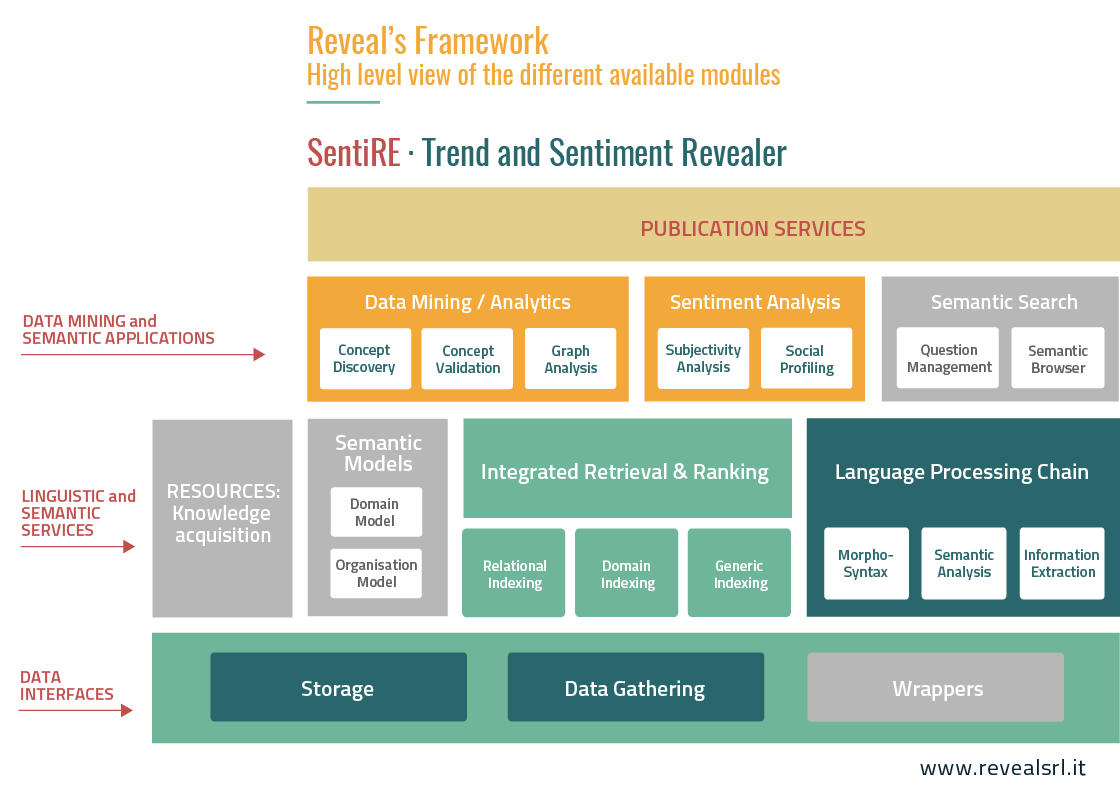
- Data interfaces: these implement the wrappers to the input document collections and allow to store the semantic indexes in dedicated data-lakes.
- Linguistic and Semantic services: these implement the linguistic analysis of input documents, storage and manipulation of organizational models as well as the indexing of the input material.
- Data mining and semantic applications: the data mining services allow processing the entire document collection to automatically locate and synthesize conceptualizations useful to enrich the input documents with metadata reflecting their content. Semantic search modules allow the deep understanding of the user queries and enable a semantically driven browsing of the document collection (e.g., through semantic graphs).
- Publication services: the publication services enable interaction with the final user, generally through Web-applications that can be customized according to the clients’ needs.